News
Interference-aware Orchestration in Kubernetes
Nowadays, there is an increasing number of workloads executed on the Cloud. Although multi-tenancy has gained a lot of attention to optimize resource efficiency, current state-of-the-art resource orchestrators rely on typical metrics, such as CPU or memory utilization, for placing incoming workloads on the available pool of resources, thus, neglecting the interference effects from workload co-location. Within EVOLVE, we have designed an interference-aware cloud orchestrator, based on micro-architectural event monitoring. We integrate our solution with Kubernetes achieving higher performance, up to 32% compared to its default scheduler, for a variety of cloud workloads.
Workloads placed on the same physical machines continuously contest for shared resources, such as cache, memory occupancy, memory/network bandwidth and others, causing interference to each other, which, in turn, induces huge negative impact on their performance. Multi-sharing and multi-diversity of resources can cause serious degradation on the performance of running applications, thus the need for interference-aware scheduling of incoming workloads on a cluster is indispensable.
Recently, HPC and Cloud worlds are getting more and more close. The latest advancements and performance improvements of container-based virtualization have driven many HPC applications to be containerized, enabling increased productivity through prompt and seamless updates and rollbacks to previous versions. Indeed, the current trend for the scheduling of arriving workloads on a pool of available resources even in HPC environments [1] is through container orchestrators, such as Kubernetes [2] which provide a common environment for the whole infrastructure, be it on-premises or in the cloud. Even though container orchestrators provide major benefits, such as ease of use and deployment, abstraction of resources, scaling and others, they are focusing mostly on availability rather than performance optimization, relying on coarse metrics, e.g. CPU or memory utilization, thus neglecting interference effects, overlooking the specifications of the underlying infrastructure and the nature of the imposed stress on the shared resources. Contention on the low-level shared resources of a system, i.e. low-level caches and bus bandwidth, can lead to unpredictable performance variability [3],[4] and degradation, which highly reduces the QoS of applications [5].
The default Kubernetes scheduler consists of two different stages. First, it determines all the feasible nodes and then using a set of scoring functions, it rates each remaining node and determines the most viable one. Although kube-scheduler usually favors the node with the least requested per capacity ratio (RAM, CPUs), this results in suboptimal pod placements, even in simple deployment scenarios. As a motivational example, we assigned kube-scheduler the task to schedule a pod on a small cluster of two VMs v1 (4 vcpus, 8GB RAM) and v2 (8 vcpus, 16GB of RAM), in which there were already deployed some resource-stressing micro-benchmarks from the iBench suite [6]. After multiple tests, the scheduler consistently favored v2. However, by placing the aforementioned application in v1, we achieved an average speedup of 1.46x.
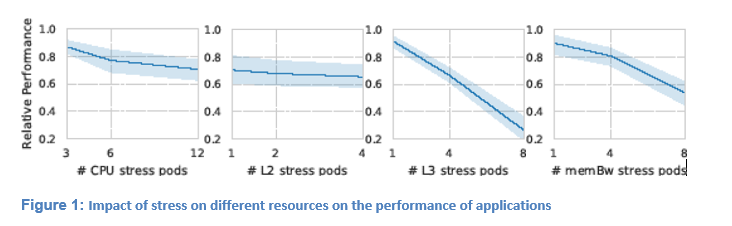
In order to evaluate the impact of each kind of resource stress on the performance of applications, we tentatively co-schedule workloads from different classes (e.g spec2006, scikit-learn, cloudsuite) with iBench. Figure 1 depicts the relative performance (y-axis) of all our target workloads when co-scheduled with different numbers (x-axis) of specific resource-stressing, iBench micro-benchmarks. The solid line in each plot shows the estimate of the central tendency of the relative performance while the surrounding area illustrates the confidence interval for that estimate. This plot reveals that, as the resource interference moves higher in the memory hierarchy, the impact on the performance increases exponentially. Specifically, we notice that stressing the LLC has the greatest effect on the performance of our workloads.
In this work, using hardware event monitoring, we implemented an integrated with Kubernetes, two-level, custom node prioritization logic. As we have pinned underlying system's sockets and their respecting cores in separate VMs, we are able to have insight and take advantage of the real system metrics. While resources such as memory bandwidth and LLC are shared between cores in the same socket, in the first level of our approach we select the most appropriate socket. We address both interference effects and core availability using a custom score constructed by low-level hardware counters. In the second level, we select the node (VM) with the highest core availability. Within EVOLVE and by using our custom scheduler for Kubernetes deployments, we achieve a more balanced resource utilization between computing nodes, while also reducing the average execution time of the running workloads by 20%.

References
1. Yenier, D.G., Wolfgang Gentzsch, U.: Kubernetes and hpc applications in hybrid cloud environments – part ii (March 2020)
2. Burns, B., Grant, B., Oppenheimer, D., Brewer, E., Wilkes, J.: Borg, omega, and kubernetes (2016)
3. Zhuravlev, S., Blagodurov, S., Fedorova, A.: Addressing shared resource contention in multicore processors via scheduling. In: ACM Sigplan Notices. vol. 45, pp. 129–142. ACM (2010)
4. Guo, J., Chang, Z., Wang, S., Ding, H., Feng, Y., Mao, L., Bao, Y.: Who limits the resource efficiency of my datacenter: an analysis of alibaba datacenter traces. In: Proceedings of the International Symposium on Quality of Service. p. 39. ACM(2019)
5. Lo, D., Cheng, L., Govindaraju, R., Ranganathan, P., Kozyrakis, C.: Heracles: Improving resource efficiency at scale. In: ACM SIGARCH Computer Architecture News. vol. 43, pp. 450–462. ACM (2015)
6. Delimitrou, C., Kozyrakis, C.: ibench: Quantifying interference for datacenter applications. In: 2013 IEEE international symposium on workload characterization(IISWC). pp. 23–33. IEEE (2013)