News
Exploration of GPU sharing policies under GEMM workloads
Lately, cloud computing has seen explosive growth, due to the flexibility and scalability it offers. The ever-increasing computational demands, especially from the machine learning domain, have forced cloud operators to enhance their infrastructure with acceleration devices, such as General-Purpose (GP)GPUs or FPGAs.
Even though multi-tenancy has been widely examined for conventional CPUs, this is not the case for accelerators. In this work, we analyse the potentials of GPU sharing inside data-center environments. We investigate how several architectural features affect the performance of GPUs under different multi-tenant stressing scenarios and we compare CUDA MPS with the native, default CUDA scheduler and also with Vinetalk, a research framework providing GPU sharing capabilities. The experimental results show that NVIDIA's MPS achieves the best performance in multi-application scenarios, specifically up to x4.5 and x11.2 compared to native CUDA scheduler and Vinetalk respectively.
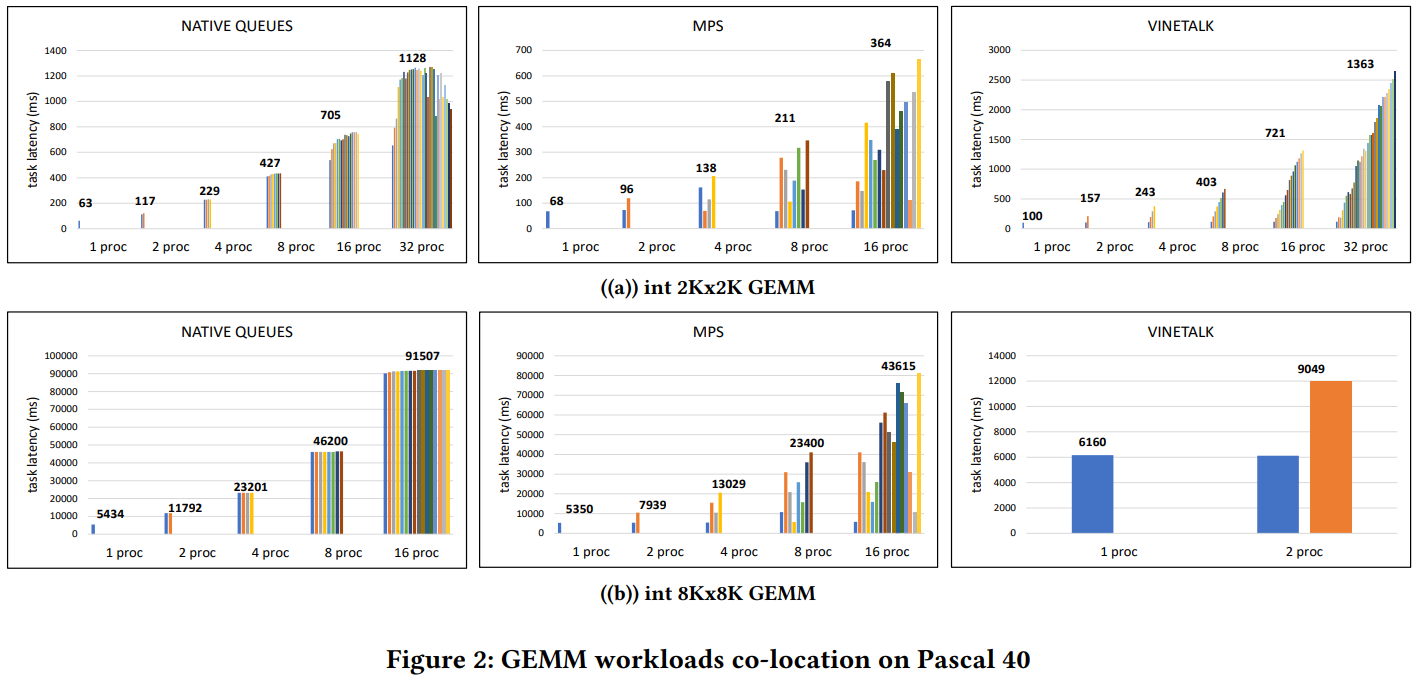
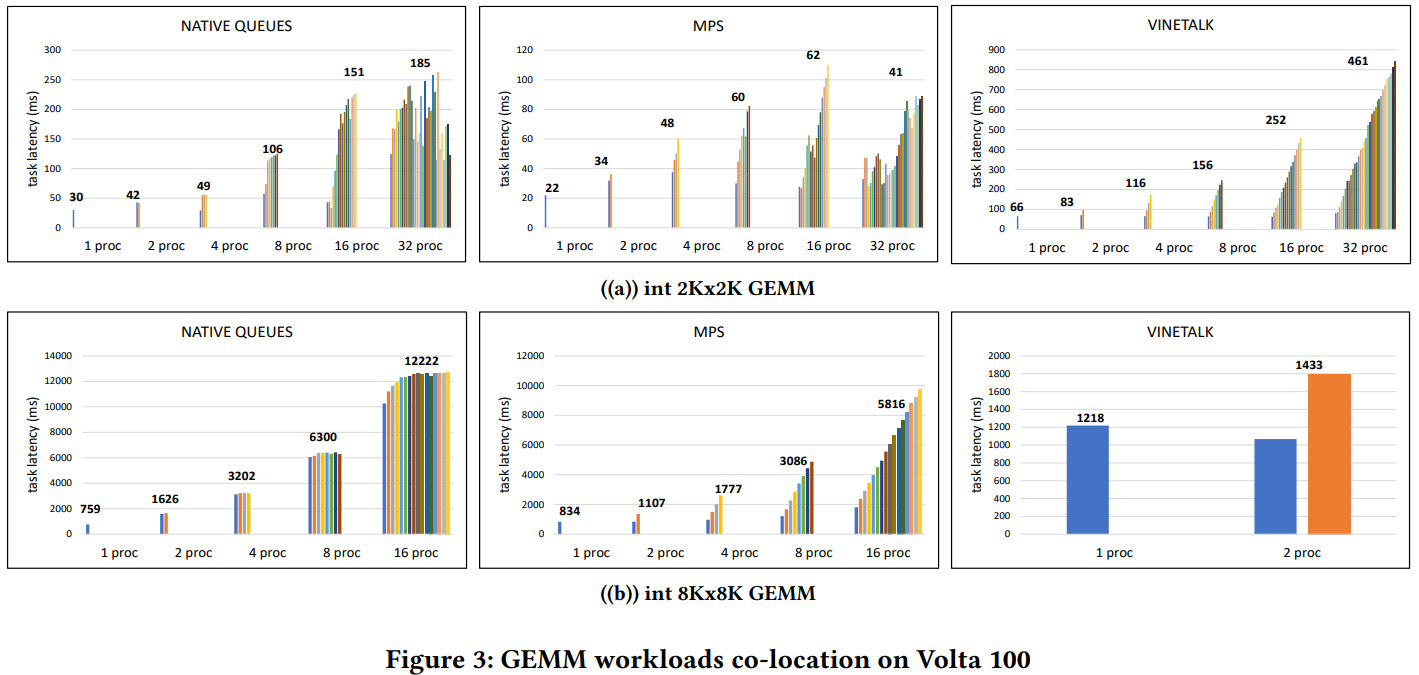
Considering General Matrix Multiplication (GEMM) workloads as our target applications, we focus on Tesla K20, Tesla P40 and Tesla V100 NVIDIA GPUs and their scheduling policies for workloads co-location. Note that that Pascal 40 and Volta 100 provide a preemptive scheduler in contrast with Kepler 20. In order to analyse the single and multi-task performance of various GPUs, 1, 2, 4, 8, 16 and 32 instances of 2048x2048 and 8192x8192 integer GEMM CUDA routines are concurrently submitted on a single GPU. Each instance's latency is depicted with native queues, MPS and Vinetalk framework as schedulers. Task latency in figures refers to the sum of CUDA kernel, transfer and data allocation time while the number at the top of the bars constitutes the average task latency in milliseconds.
Experimental results in Figures 1, 2 and 3 disclose architectural indications in terms of task co-location. Architectural weaknesses are revealed as well, as innate system constraints and memory limit allow us testing up to 4 concurrent tasks for native and MPS scheduling and only 2 for Vinetalk scheduling in the worst cases. The maximum possible number of tasks has been recorded in all Figures. It is worth pointing out how clear are the specific features of each scheduler just by observing the corresponding execution times of the tasks. Native queues seem to apply a type of fairness in a pseudo-concurrent context while slicing internally the tasks. Conversely, MPS scheduler varies from generation to generation. It follows a random scheme of task serving in pre-Volta, while it follows a First-In-First-Out scheme in Volta GPUs. Finally, Vinetalk seems to follow a clear temporal First-Come First-Served policy internally in all GPUs. Finally, MPS proves to be the most efficient solution despite the build-in limits it acquires in the pre-Volta architectures. Vinetalk offers the second optimal solution in most cases whenever it does not fail due to architectural limits. Additionally, native queues seem to be the less efficient but the fairest and safest solution.