News
Dataset Lifecycle Framework: the swiss army knife for data source management in Kubernetes
Hybrid Cloud is rapidly becoming the go-to IT strategy for organizations seeking the perfect mix of scalability, performance and security. As a result, it is now common for an organization to rely on a mix of on-premise and cloud solutions, or “data-sources”, from different providers to store and manage their data.
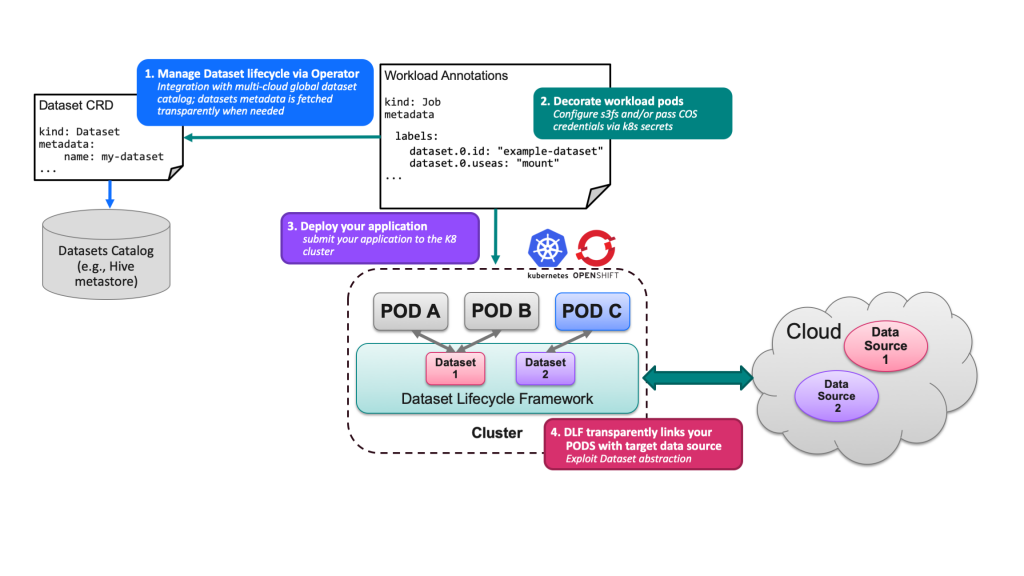
The Dataset Lifecycle Framework Flow
It doesn’t really sound problematic, not until applications have to access the data. Developers need to know the data location and have the credentials to access the specific data-source holding their data. With the advent of regulations like GDPR users also need to be aware of which data-centres can host that data. Meanwhile, access to cloud storage is often completely transparent from the cloud management standpoint and infrastructure administrators have almost no tools for monitoring which pods are accessing which cloud storage solution.
What if tomorrow your data gets migrated to a different cloud provider or you have to work on different data? To avoid issues you would need to ensure you always had the correct information to access the correct data-source. Or again if you want to share a dataset with someone else in the same organization you’d need multiple manual configuration steps to get them access … and then wait for the inevitable emails about expired credentials.
If these issues sound familiar, then our Dataset Lifecycle Framework (DLF) is coming to your rescue. It is a Kubernetes native ‘swiss army knife’ to ease working with data-sources for containerized applications.
DLF is an open source project that enables transparent and automated access to data-sources. Users create a “Dataset” resource, which defines how to access particular data in a specific data-source and gives it an easy to remember name. Afterwards any developer requiring access to that data needs only to specify this name. DLF takes care of making the data available to the application in the way the application expects it: if the data-source is an NFS export it will get mounted at the correct location; if the data-source is a bucket in Cloud Object Storage, the access credentials and endpoint will be injected to your containers as environment variables or mounted in the file system. Furthermore, if there is some change in the remote data-source only the “Dataset” needs to be updated – applications using it will remain totally oblivious to this change. On the infrastructure side, DLF also helps by enabling cluster administrators to easily monitor, control, audit data access.
At present DLF can be installed in any Kubernetes or Openshift cluster. It supports all data sources using the AWS S3 API and we are currently working on enabling different types of data-sources such as NFS.
Improving Cloud Storage Access Performance with DLF
In addition to pure management of the data-set life-cycle, DLF improves storage access performance by transparently caching remote data on local cluster storage. This can reduce accesses to the remote cloud storage and hence demands on the external network, improving throughput.
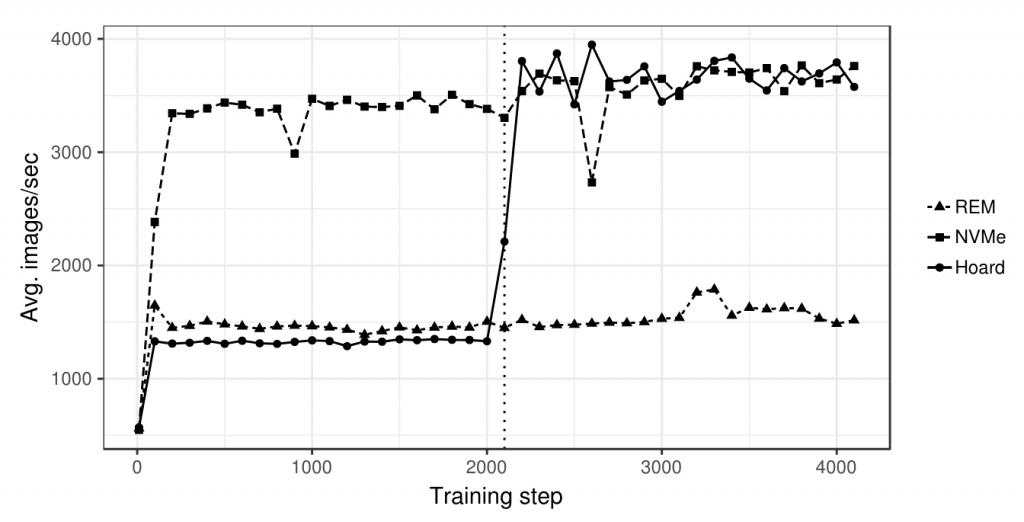
Effect of transparent caching over local NVMes for 4xGPU Alexnet Training (REM: training from remote data source; NVMe: Training directly from local NVMe; Hoard: Training using our transparent caching mechanism)
For example, imagine Deep Learning models trained with multiple GPUs and whose training datasets are stored in Cloud Object Storage. In this scenario it is not possible to keep the GPUs at 100% during the whole training mostly because the cloud storage throughput is not high enough. The result is a waste of precious GPU computing time. This scenario itself was the birthplace of DLF. We built a transparent caching system leveraging an on-premise distributed file system (IBM Spectrum Scale) to enable near local storage bandwidth when accessing training data. Transparency from applications point of view was enabled via a new Kubernetes Custom Resource Definition (CRD) called Dataset.
This work was carried out by our team with support from the IBM Research labs in Yorktown Heights and Zurich, and was sponsored by the IBM GCDO office. You can read more about this phase here [https://arxiv.org/abs/1812.00669]. We are working on bringing this functionality to the open source DLF project soon.
What’s next
As mentioned above we are targeting support for data caching on local cluster storage resources and a plugin-based system to allow developers to choose their preferred storage backend for the cache during first half of next year.
In our roadmap we are also targeting on integrating with existing data-lake technologies e.g. Hive, to further automate the process of Datasets creation. Our vision is that users will just need to point to the data-source in the catalogue they want to access, and the rest is done by DLF.